
OCI FortiGate HA Cluster – Reference Architecture: Code Review and Fixes
Introduction OCI Quick Start repositories on GitHub are collections of Terraform scripts and configurations provided by Oracle. These repositories ... Read More
Learn more about why Eclipsys has been named the 2023 Best Workplaces in Technology and Ontario, Certified as a Great Place to Work in Canada and named Canada’s Top SME Employer!
Learn more!Golden Gate replication solution allows you to capture, replicate, filter, transform, and deliver real-time transactional data across Oracle or heterogeneous environments.
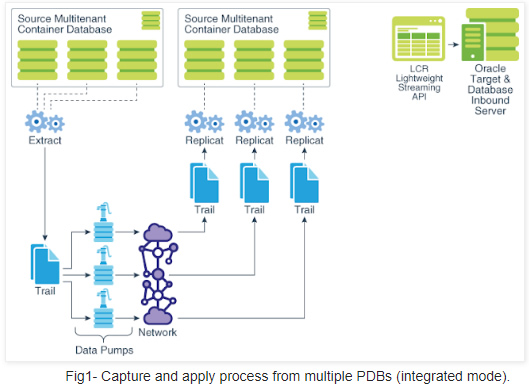
Golden Gate 12c features along with Oracle multi-tenant architecture introduced some changes to the way replication works (see Fig-1). Another interesting fact is that few of Oracle Streams features have now found their way into GoldenGate.
This article describes how to configure Oracle GoldenGate 12c in order to perform a Bi-directional replication between Oracle source and target Container Database 12c. We will be using Integrated Replicat and Integrated Extract since Integrated mode extraction is the only supported method for Multi-tenant databases.
Multitenant specificity
Here are some major changes regarding GoldenGate coupled with Oracle Database 12c multitenant architecture:
What will be covered ?
In this post we will focus on the following main steps:
I. GoldenGate Environment Configuration
II. Initial load
III. Apply change data
IV. Bi-directional replication
My lab is based on the below source and target systems. Both contain similar Pluggable database called ”PDB”

A- Installation
GoldenGate installation is pretty straightforward. Make sure you specify the right GGate and database homes
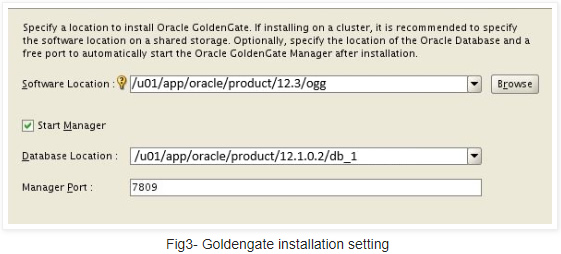
Note: If there is only one GoldenGate installation for multiple DBs you will have to set those variables in the extract and replicat processes directly as below :

B-Preparation
An extract process for a multitenant database must be created at the root container level with a “common” database user and must be defined to run in the “integrated” capture mode. Replicats, on the other hand, must be created at the pluggable database level and can be defined to run in either the “classic” or “integrated” modes.
1. On the source system (MONTREAL)
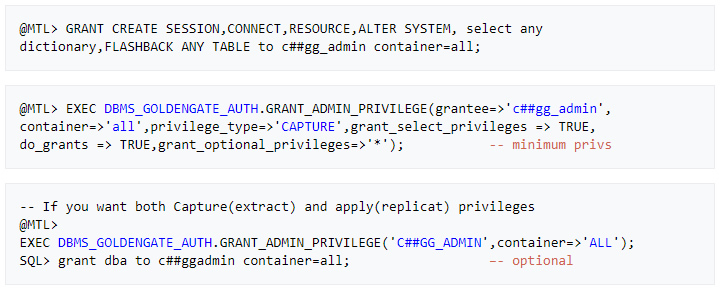
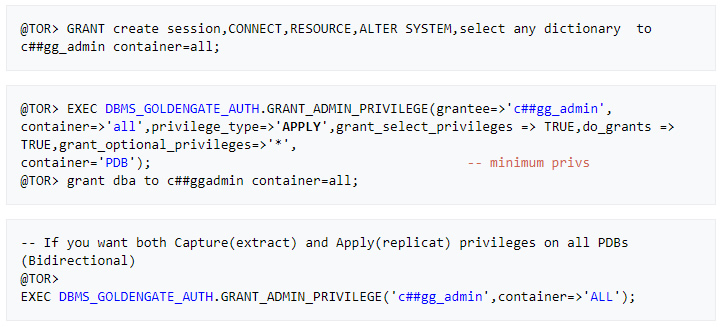
» Create source OGG admin User

– Assign the correct source privileges to the GoldenGate admin user as shown below
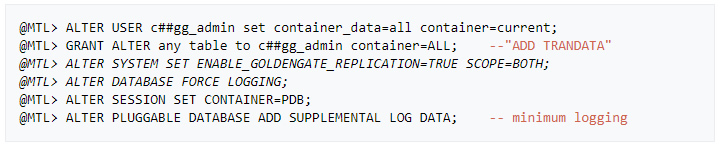
» Add supplemental log data for update operations
2. On the TARGET system (TORONTO)
» Create target OGG admin User

– Assign the right target privileges to the Golden Gate admin user as shown below
This is basically the first stage where the extract captures data directly from source tables and without using trail files.
Important: First make sure that both source and target PDB open state is permanent before setting up any replication

A- Prepare the target Tables
» (Re)Create an empty sample schema “SCOTT” on the target PDB (download script here)

Note: You can run this script @scott.sql in the source PDB if SCOTT schema is not yet created
B- Configuration
1. On the source system (MONTREAL)
» Configure OGG User alias and schema logging
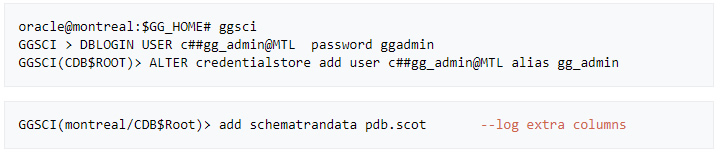
Note: This lab assumes that tns aliasses have been created for both source and target database and PDBs
@MTL= Montreal , @TOR=toronto , @PDB= PDB in each server respectively
» Allow incoming access to the Manager process

» Create an initial Extract parameter file
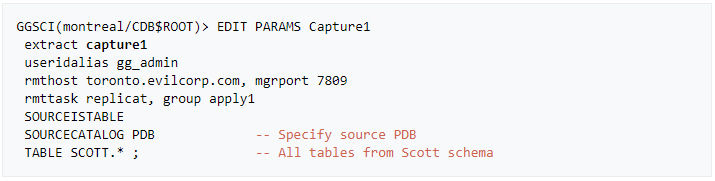
» Add and register the initial extract with the container database

2. On the TARGET system (TORONTO)
» Add OGG User alias PDB level (can be run from root CDB too)

» Allow incoming access to the Manager process

» Create a Replicat parameter file
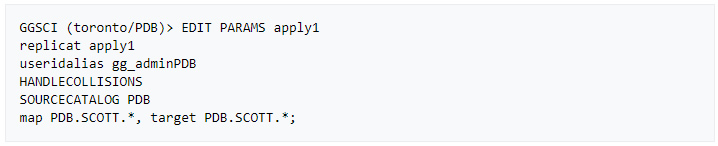
» Add the integrated replicat

» Start the extract process on the source system

This will allow the target scott schema to be synchronized in a few seconds.
Note: In case datatypes weren’t similar, a definition file is required to handle the mapping using DEFGEN utility
The extract process will pull data from the PDB and send it across the network to the target system. Once data is written to target trail files, the integrated replicat will convert it to LCRs which will be applied to target PDB by the inbound server.
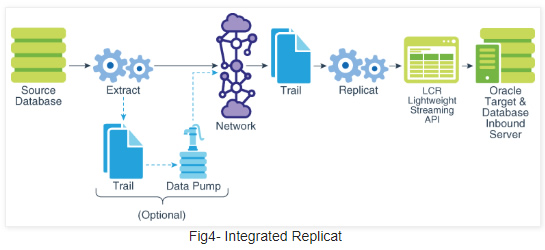
A- Configuration
1. On the source system (MONTREAL)
» Create an Integrated Primary extract

Note: TRANLOGOPTIONS is only required for bidirectional replication. I added it in purpose here.
» Add and register the integrated extract with the container database

» Create a trail for the Extract group and start it

» Create a SECONDARY EXTRACT DATA PUMP (recommended).
This is an optional component for our primary extract helping to move the trail over the network.
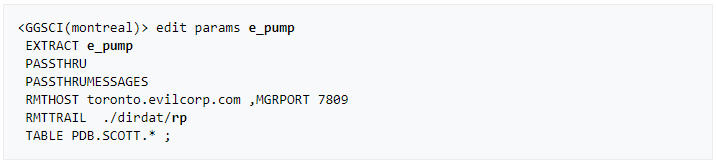
» Create and start a data pump extract

2. On the Target system (TORONTO)
» Create a Replicat parameter file
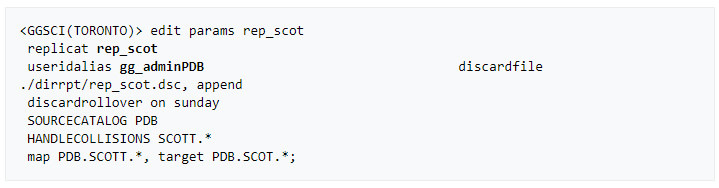
Note: No need to create a checkpoint table for the integrated replicat unless Data Guard is configured
» Add and start the integrated replicat

– Remote trail prefix should be the same as specified in the data pump parameter file (rp)
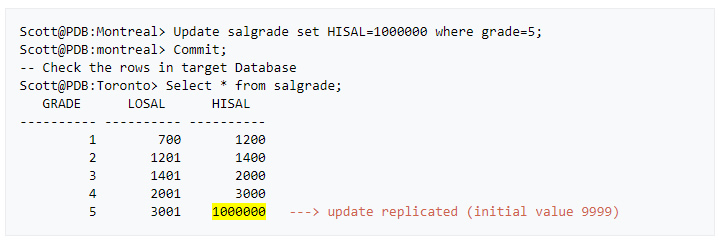
» We can now verify that the data is replicated to the target by performing a little update on the source database
When implementing a bidirectional configuration, you must consider the following areas to avoid data integrity issues:
• Loop detection ( ping pong data behaviour)
• Conflict detection and resolution (CDR) when the same column is modified at the same time on both systems
• Oracle Triggers (Replicat data triggering DML operations on the target system)
Golden Gate 12c already handles the above issues as
A- Configuration
As Extract and Replicat processes will be on both servers, I will refer to Montreal as a target and Toronto as a source.
1. On the source system (TORONTO)
» Add supplemental log data for update operations

» Configure OGG User alias and schema logging (root level)

» Verify that the right source privileges are granted to GoldenGate admin user

» Create an Integrated Primary extract

» Add and register the integrated extract with the container database

» Create a trail for the Extract group and start it

» Create a SECONDARY EXTRACT DATA PUMP
Optional but why not :).
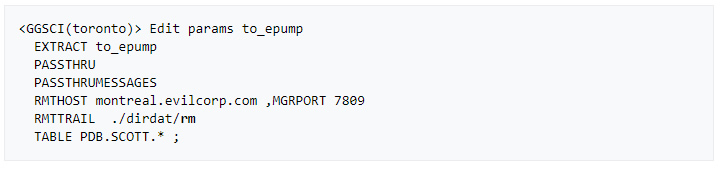
» Create and start a data pump extract

2. On the Target system (MONTREAL)
» Verify that the right source privileges are granted to GoldenGate admin user

» Create an OGG admin User (PDB level)

» Create a Replicat parameter file
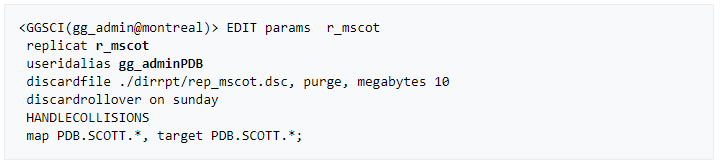
» Add and start the integrated replicat

– Remote trail prefix should be the same as specified in the data pump parameter file (rm)
B- Test & Monitoring
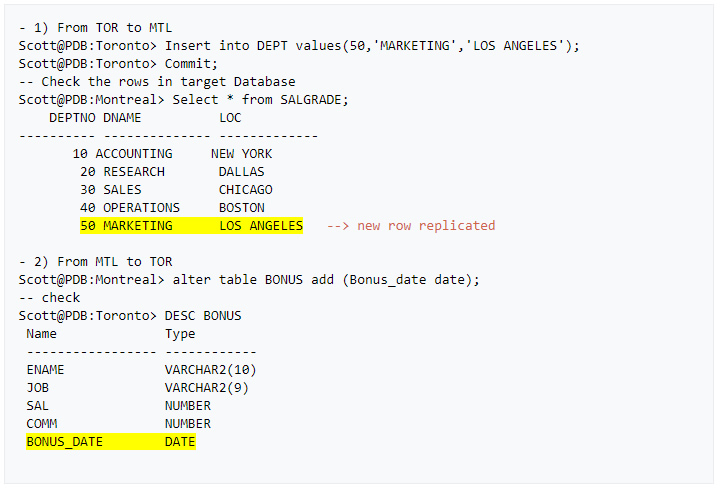
» Let’s verify if data is now replicated in both directions via an insert on the news source and a DDL on target PDB
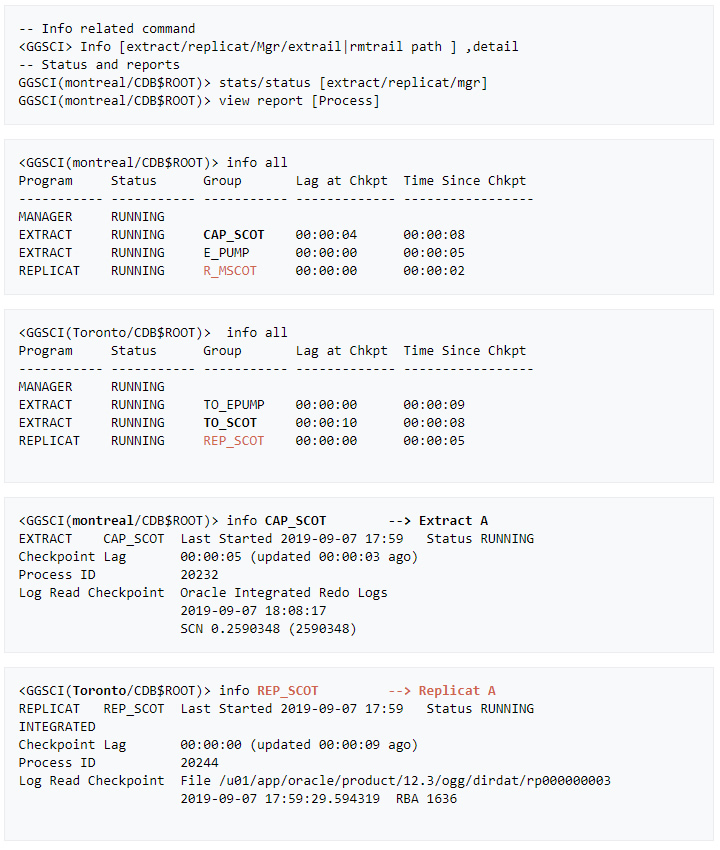
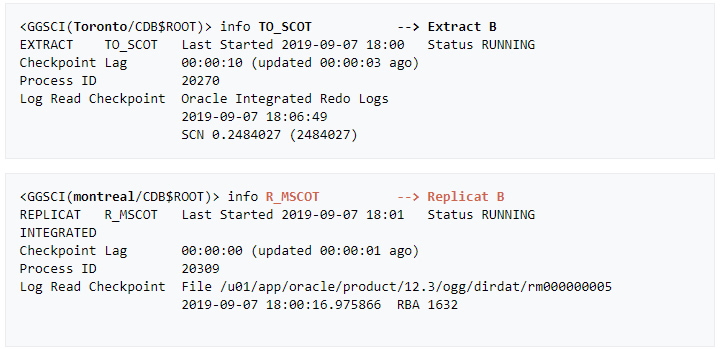
» Last but not least: Here are few GGSCI commands that help monitor the status of the replication processes.
Introduction OCI Quick Start repositories on GitHub are collections of Terraform scripts and configurations provided by Oracle. These repositories ... Read More

Introduction So far, I have used Oracle AutoUpgrade, many times in 3 different OS’. Yet the more you think you’ve seen it all and reached the ... Read More



