
Terraform Modules Simplified
Terraform is probably already the de-facto standard for cloud deployment. I use it on a daily basis deploying and destroying my tests and demo setups ... Read More
Découvrez pourquoi Eclipsys a été nommée 2023 Best Workplaces in Technology, Great Place to Work® Canada et Canada's Top 100 SME !
En savoir plus !Last week while checking my Twitter feed I found a tweet from Confluent with an announcement about a new Kafka connector for the Oracle Database as a source. We had an Oracle connector before but it was working scanning the source tables and, as a result, adding a load to the source database. But that one was different and we got a connector that could get the changes from Oracle redo logs. I started to test it using my Kafka dev environment in the Google Cloud and one of my sandbox databases in the Oracle Cloud. Here I would like to share how to start to test it and my very first experience with the tool.
The first step was to get a working Confluence Kafka deployment. You could choose either the Kafka Cloud Service on the Google Cloud platform or deploy it on your VM using RPM, zipped package or Docker. I’ve chosen the gzipped package and a standalone, development-type deployment on a single VM for my tests. The deployment is not difficult and can be done in four simple steps:
You should go first to the Confluent site and download the gzipped package. I put it to the /tmp.
confluent@kafka-srv-01 confluent]$ ll /tmp/confluent-6.1.0.tar.gz -rw-rw-r--. 1 user user 1492370693 Feb 18 18:16 /tmp/confluent-6.1.0.tar.gz
Then I created a user “confluent”, a directory “/opt/confluent” for the software and uncompressed the downloaded package to that directory.
[confluent@kafka-srv-01 confluent]$ ll /tmp/confluent-6.1.0.tar.gz -rw-rw-r--. 1 gleb_otochkin gleb_otochkin 1492370693 Feb 18 18:16 /tmp/confluent-6.1.0.tar.gz [confluent@kafka-srv-01 confluent]$ cd /opt/confluent/ [confluent@kafka-srv-01 confluent]$ tar xfz /tmp/confluent-6.1.0.tar.gz [confluent@kafka-srv-01 confluent]$
The next step was to get the connectors for Oracle CDC and for BigQuery.
[confluent@kafka-srv-01 confluent]$ cd confluent-6.1.0/ [confluent@kafka-srv-01 confluent-6.1.0]$ confluent-hub install --no-prompt confluentinc/kafka-connect-oracle-cdc:latest Running in a "--no-prompt" mode Implicit acceptance of the license below: Confluent Software Evaluation License https://www.confluent.io/software-evaluation-license Downloading component Kafka Connect OracleCDC Connector 1.0.3, provided by Confluent, Inc. from Confluent Hub and installing into /opt/confluent/confluent-6.1.0/share/confluent-hub-components Adding installation directory to plugin path in the following files: /opt/confluent/confluent-6.1.0/etc/kafka/connect-distributed.properties /opt/confluent/confluent-6.1.0/etc/kafka/connect-standalone.properties /opt/confluent/confluent-6.1.0/etc/schema-registry/connect-avro-distributed.properties /opt/confluent/confluent-6.1.0/etc/schema-registry/connect-avro-standalone.properties Completed [confluent@kafka-srv-01 confluent-6.1.0]$ confluent-hub install --no-prompt wepay/kafka-connect-bigquery:latest Running in a "--no-prompt" mode Implicit acceptance of the license below: Apache License 2.0 https://www.apache.org/licenses/LICENSE-2.0 Implicit confirmation of the question: You are about to install 'kafka-connect-bigquery' from WePay, as published on Confluent Hub. Downloading component BigQuery Sink Connector 2.1.0, provided by WePay from Confluent Hub and installing into /opt/confluent/confluent-6.1.0/share/confluent-hub-components Adding installation directory to plugin path in the following files: /opt/confluent/confluent-6.1.0/etc/kafka/connect-distributed.properties /opt/confluent/confluent-6.1.0/etc/kafka/connect-standalone.properties /opt/confluent/confluent-6.1.0/etc/schema-registry/connect-avro-distributed.properties /opt/confluent/confluent-6.1.0/etc/schema-registry/connect-avro-standalone.properties Completed [confluent@kafka-srv-01 confluent-6.1.0]$
Everything was ready to start my small Confluent Kafka deployment.
[confluent@kafka-srv-01 confluent-6.1.0]$ confluent local services start The local commands are intended for a single-node development environment only, NOT for production usage. https://docs.confluent.io/current/cli/index.html Using CONFLUENT_CURRENT: /tmp/confluent.745607 Starting ZooKeeper ZooKeeper is [UP] Starting Kafka Kafka is [UP] Starting Schema Registry Schema Registry is [UP] Starting Kafka REST Kafka REST is [UP] Starting Connect Connect is [UP] Starting ksqlDB Server ksqlDB Server is [UP] Starting Control Center Control Center is [UP] [confluent@kafka-srv-01 confluent-6.1.0]$
That was a development environment and it is not suited for production. If you want to deploy a production you need to plan and deploy it according to your requirements or use, as I’ve already mentioned, the Confluent Cloud.
On the source side, I created an Oracle sandbox database in the Oracle cloud. For the test, I used a 12.2.0.1 container(multitenant) database with one PDB. All the requirements and preparation steps are perfectly described in the Confluent documentation. In short, you need a user with privileges to use logminer and access to the dictionary views, the database or table level supplemental logging enabled for all columns and the database should be in archive log mode. In my case, I used Oracle 12.2 EE version. The connector supports 12.2 and 18c versions. The 19c version is not supported as of now. Inside my PDB I created a schema SCOTT and one test table.
oradb> CREATE TABLE scott.test_user_objects AS SELECT * FROM dba_objects WHERE object_id<11; TABLE created. oradb>
I had the Kafka up and running and could try our Oracle CDC connector. For the first tests, I tried to use the Control Center to check if it is fully sufficient to make it work. You could access the Control Center by using URL http://<your Conlfluent VM hostname>:9021/

There you could go to the connector page and add a new connector for source or for the sink(destination).

I selected the “OracleCDCSourceConnector” and filled up the base information about the connector, connection information for my PDB and the “table.inclusion.regex”: “TESTPDB.SCOTT.*” to include all the tables for the user SCOTT in my “TESTPDB” pluggable database.

I deliberately tried to use a minimum of the custom parameters to find out if the default values are sufficient to start with the testing. It almost worked and but I hit some problems.
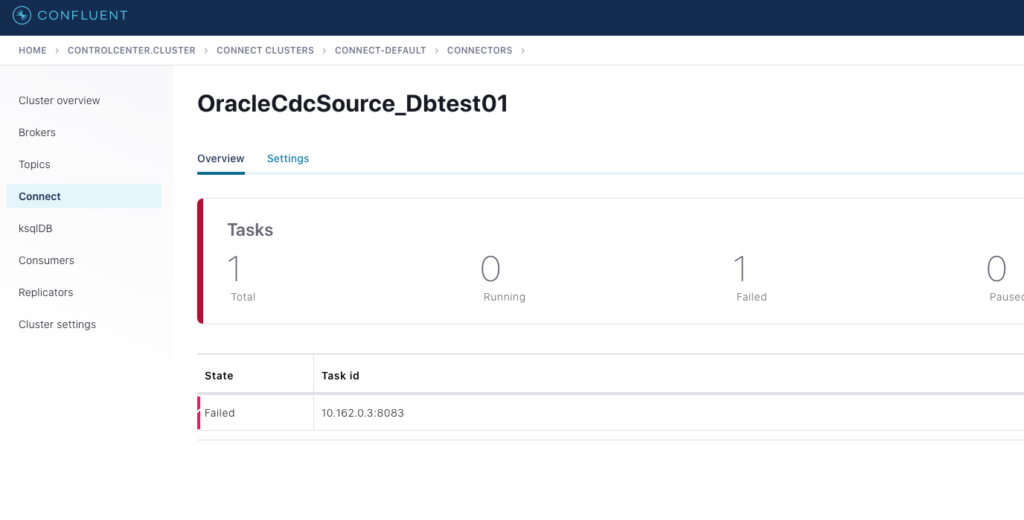
The first problem was related to the parameter “schema.registry.url” .
[confluent@kafka-srv-01 ~]$ tail -f /tmp/confluent.745607/connect/logs/connect.log ... [2021-02-22 19:34:41,640] INFO Instantiated task OracleCdcSource_Dbtest01-0 with version 1.0.3 of type io.confluent.connect.oracle.cdc.OracleCdcSourceTask (org.apache.kafka.connect.runtime.Worker:538) [2021-02-22 19:34:41,645] ERROR Failed to start task OracleCdcSource_Dbtest01-0 (org.apache.kafka.connect.runtime.Worker:574) org.apache.kafka.common.config.ConfigException: Missing required configuration "schema.registry.url" which has no default value.
I was able to figure out that it was related to the Avro converted and put both parameters as additional properties to the configuration. You can see the two additional parameters “value.converter.schema.registry.url” and “key.converter.schema.registry.url” (unfortunately the names are truncated by the interface).
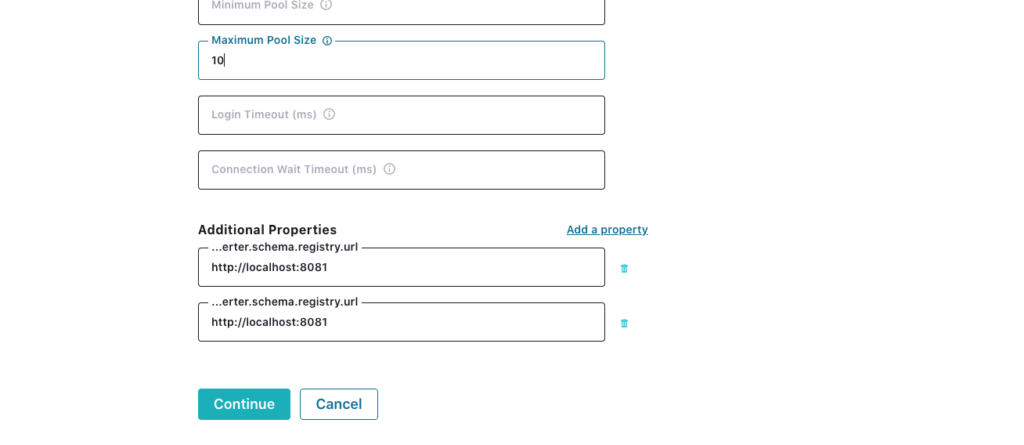
Then I got some problems with bootstrap servers, but after setting them up it started to work. I think it would be probably nice to have them as required parameters in configuration. And here is the minimal configuration file for the source Oracle CDC connector.
{
"value.converter.schema.registry.url": "http://localhost:8081",
"key.converter.schema.registry.url": "http://localhost:8081",
"name": "OracleCdcSource_Dbtest01",
"connector.class": "io.confluent.connect.oracle.cdc.OracleCdcSourceConnector",
"tasks.max": "1",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"oracle.server": "dbtest12",
"oracle.port": "1521",
"oracle.sid": "oradb",
"oracle.pdb.name": "TESTPDB",
"oracle.username": "C##KAFKA",
"oracle.password": "************************",
"redo.log.consumer.bootstrap.servers": [
"localhost:9092"
],
"table.inclusion.regex": "TESTPDB.SCOTT.*",
"connection.pool.max.size": "10",
"confluent.topic.bootstrap.servers": [
"localhost:9092"
]
}
If you prefer the command line to the web interface you can use the JSON file and REST API to configure the connector. Here is an example:
[confluent@kafka-srv-01 ~]$ vi connector_OracleCdcSource_Dbtest01.json [confluent@kafka-srv-01 ~]$ curl -s -H "Content-Type: application/json" -X POST -d @connector_OracleCdcSource_Dbtest01.json http://localhost:8083/connectors/
We can see the task is up and running either from the web interface or executing a REST call.
[confluent@kafka-srv-01 confluent-6.1.0]$ curl -s -X GET -H 'Content-Type: application/json' http://localhost:8083/connectors/OracleCdcSource_Dbtest01/status | jq { "name": "OracleCdcSource_Dbtest01", "connector": { "state": "RUNNING", "worker_id": "10.***.***.3:8083" }, "tasks": [ { "id": 0, "state": "RUNNING", "worker_id": "10.***.***.3:8083" } ], "type": "source" } [confluent@kafka-srv-01 confluent-6.1.0]$
And we could read messages from the automatically created topic TESTPDB.SCOTT.TEST_USER_OBJECTS :
[confluent@kafka-srv-01 confluent-6.1.0]$ kafka-topics --list --zookeeper localhost:2181 | grep SCOTT TESTPDB.SCOTT.TEST_USER_OBJECTS confluent@kafka-srv-01 confluent-6.1.0]$ kafka-avro-console-consumer --topic TESTPDB.SCOTT.TEST_USER_OBJECTS --partition 0 --offset earliest --bootstrap-server localhost:9092 --property schema.registry.url=http://localhost:8081 [2021-02-22 20:23:41,840] WARN Ignoring invalid logical type for name: decimal (org.apache.avro.LogicalTypes:108) [2021-02-22 20:23:41,845] WARN Ignoring invalid logical type for name: decimal (org.apache.avro.LogicalTypes:108) [2021-02-22 20:23:41,845] WARN Ignoring invalid logical type for name: decimal (org.apache.avro.LogicalTypes:108) [2021-02-22 20:23:41,846] WARN Ignoring invalid logical type for name: decimal (org.apache.avro.LogicalTypes:108) [2021-02-22 20:23:41,846] WARN Ignoring invalid logical type for name: decimal (org.apache.avro.LogicalTypes:108) [2021-02-22 20:23:41,852] WARN Ignoring invalid logical type for name: decimal (org.apache.avro.LogicalTypes:108) [2021-02-22 20:23:41,852] WARN Ignoring invalid logical type for name: decimal (org.apache.avro.LogicalTypes:108) {"OWNER":{"string":"SYS"},"OBJECT_NAME":{"string":"C_OBJ#"},"SUBOBJECT_NAME":null,"OBJECT_ID":{"bytes":"v.Ôg!=ÑòÅZg_4÷) °úoÏÑ\u000BeÍ\u001Eo·rÍ\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000"},"DATA_OBJECT_ID":{"bytes":"v.Ôg!=ÑòÅZg_4÷) °úoÏÑ\u000BeÍ\u001Eo·rÍ\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000"},"OBJECT_TYPE":{"string":"CLUSTER"},"CREATED":{"int":17192},"LAST_DDL_TIME":{"int":17192},"TIMESTAMP":{"string":"2017-01-26:13:52:53"},"STATUS":{"string":"VALID"},"TEMPORARY":{"string":"N"},"GENERATED":{"string":"N"},"SECONDARY":{"string":"N"},"NAMESPACE":{"bytes":"\u0001't\u0001Ó\u0019¿ÞfØmb\u0002n\u0004içúö\u0011ºr\u0017~ïÌJ\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000\u0000"},"EDITION_NAME":null,"SHARING":{"string":"METADATA LINK"},"EDITIONABLE":null,"ORACLE_MAINTAINED":{"string":"Y"},"APPLICATION":{"string":"N"},"DEFAULT_COLLATION":null,"DUPLICATED":{"string":"N"},"SHARDED":{"string":"N"},"CREATED_APPID":null,"CREATED_VSNID":null,"MODIFIED_APPID":null,"MODIFIED_VSNID":null,"table":{"string":"TESTPDB.SCOTT.TEST_USER_OBJECTS"},"scn":{"string":"2138180"},"op_type":{"string":"R"},"op_ts":null,"current_ts":{"string":"1614023540833"},"row_id":null,"username":null} ...redacted ...
The entire table was put to the topic as the initial data snapshot with “op_type”=”R” where op_type is the operations type. I ran a couple of inserts to make sure it was working. The next step was to set up a sink connector for Big Query.
The first step for that was to create a service account in the Google cloud and to give to that account the “Big Data Editor” role.
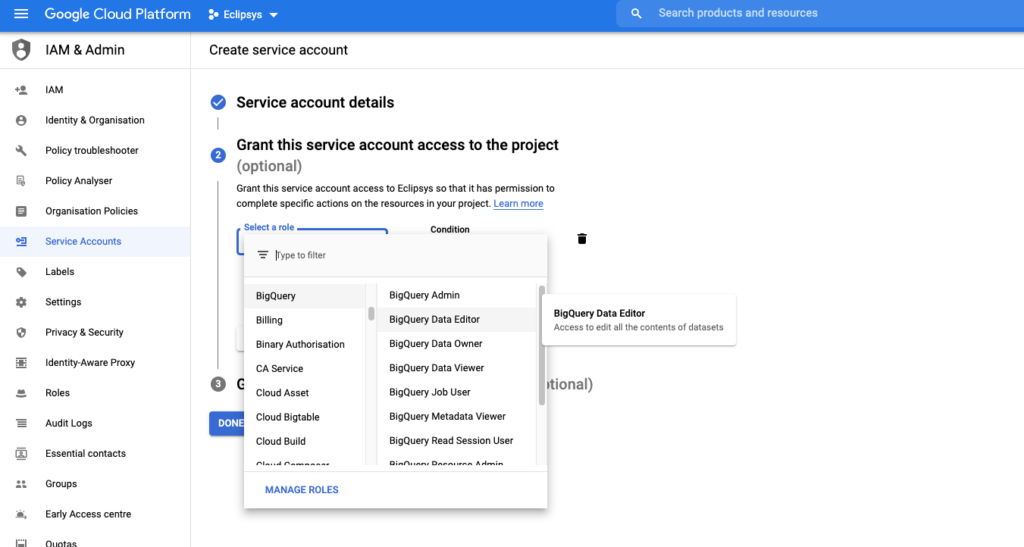
When you have the account you can create the key to be used further in the Big Query connector configuration.
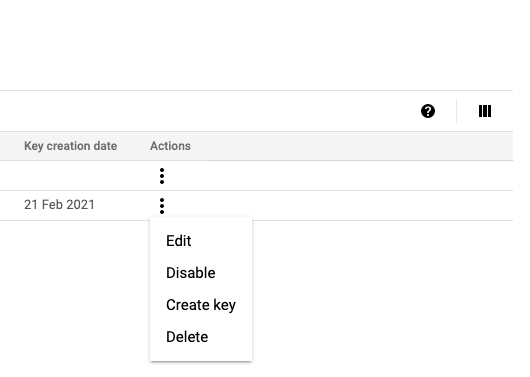
After creation, I copied the key to my Kafka machine.
Then we should create a dataset for our future tables where the data will be replicated from our topics.
gleb_otochkin@cloudshell:~ (eclipsys)$ bq mk OracleCdcSource_Dbtest01 Dataset 'eclipsys:OracleCdcSource_Dbtest01' successfully created. gleb_otochkin@cloudshell:~ (eclipsys)$
In the GCP console, we could see our new dataset.
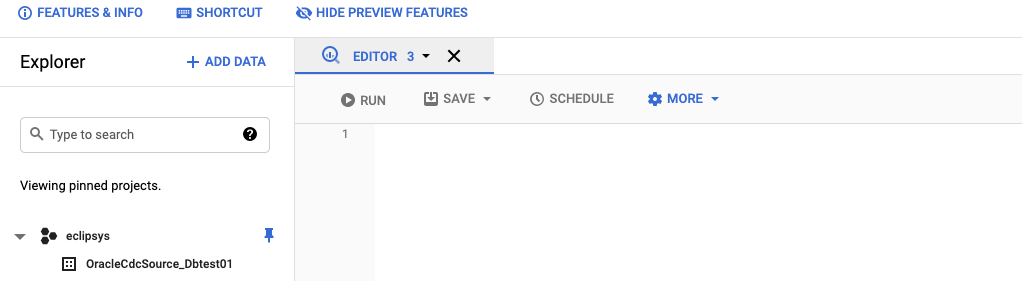
After that, we were ready to add the Big Query sink connector configuration to our Kafka deployment. The TESTPDB.SCOTT.TEST_USER_OBJECTS topic was going to be our source and the newly created dataset was our target. Here is a configuration for the connector.
{
"name": "BigQuerySink_TEST_USER_OBJECTS",
"config": {
"connector.class": "com.wepay.kafka.connect.bigquery.BigQuerySinkConnector",
"topics": "TESTPDB.SCOTT.TEST_USER_OBJECTS",
"project": "eclipsys",
"defaultDataset": "OracleCdcSource_Dbtest01",
"keyfile": "/home/confluent/eclipsys_bq_key.json",
"sanitizeTopics": "true",
"sanitizeFieldNames": "true",
"autoCreateTables": "true"
}
}
You could either add it manually in the web control center interface as we’ve done for Oracle CDC or use the REST interface.
[confluent@kafka-srv-01 ~]$ vi connector_BigQuerySink_TEST_USER_OBJECTS_config.json [confluent@kafka-srv-01 ~]$ curl -s -H "Content-Type: application/json" -X POST -d @connector_BigQuerySink_TEST_USER_OBJECTS_config.json http://localhost:8083/connectors/ {"name":"BigQuerySink_TEST_USER_OBJECTS","config":{"connector.class":"com.wepay.kafka.connect.bigquery.BigQuerySinkConnector","topics":"TESTPDB.SCOTT.TEST_USER_OBJECTS","project":"eclipsys","defaultDataset":"OracleCdcSource_Dbtest01","keyfile":"/home/confluent/eclipsys_bq_key.json","sanitizeTopics":"true","sanitizeFieldNames":"true","autoCreateTables":"true","name":"BigQuerySink_TEST_USER_OBJECTS"},"tasks":[],"type":"sink"}[confluent@kafka-srv-01 ~]$
And we could check the task using either command-line interface
[confluent@kafka-srv-01 ~]$ curl -s -X GET -H 'Content-Type: application/json' http://localhost:8083/connectors/BigQuerySink_TEST_USER_OBJECTS/status | jq { "name": "BigQuerySink_TEST_USER_OBJECTS", "connector": { "state": "RUNNING", "worker_id": "10.162.0.3:8083" }, "tasks": [ { "id": 0, "state": "RUNNING", "worker_id": "10.162.0.3:8083" } ], "type": "sink" } [confluent@kafka-srv-01 ~]$
Or through the command center:

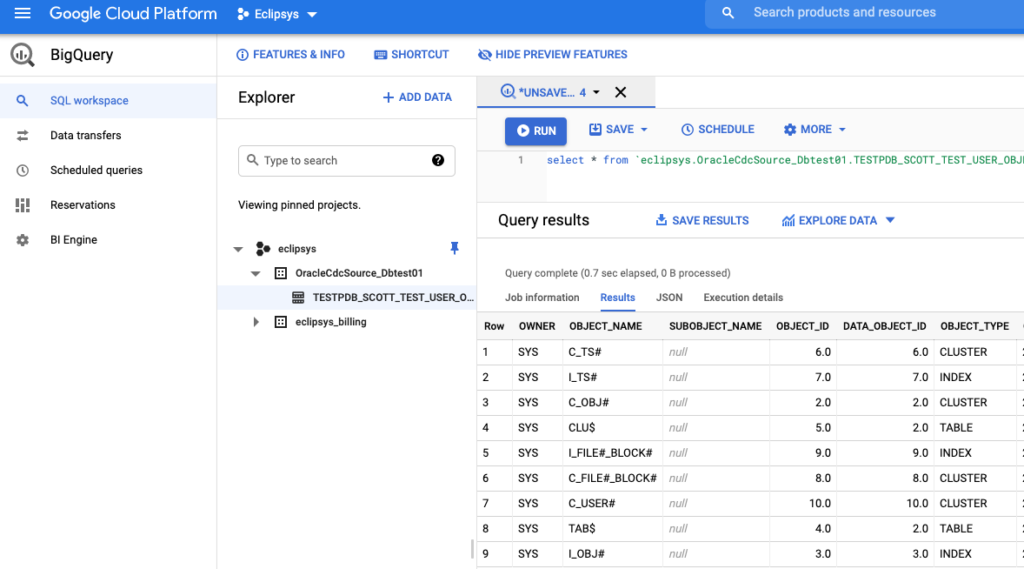
And when we looked to the Google Cloud Big Query we could see the new table with data was there. As you can see the table was created with the name “TESTPDB_SCOTT_TEST_USER_OBJECTS” which is derived from the source topic name with some minor changes (it is regulated by the “sanitizeTopics” parameter). And to get data from the Big Query table you put your project name (optional), data set name and the table name. Here is an example :
SELECT * FROM `eclipsys.OracleCdcSource_Dbtest01.TESTPDB_SCOTT_TEST_USER_OBJECTS`
After updating, inserting and deleting some records on the source Oracle database we could see the new records were added to the Big Table with different “op_type” like “I”,”D”,”U”
oradb> INSERT INTO scott.test_user_objects SELECT * FROM dba_objects WHERE object_id=11; 1 ROW created. oradb> commit; Commit complete. oradb> UPDATE scott.test_user_objects SET object_name='Test update' WHERE object_id=10; 1 ROW updated. oradb> commit; Commit complete. oradb> DELETE FROM scott.test_user_objects WHERE object_id=9; 1 ROW deleted. oradb>
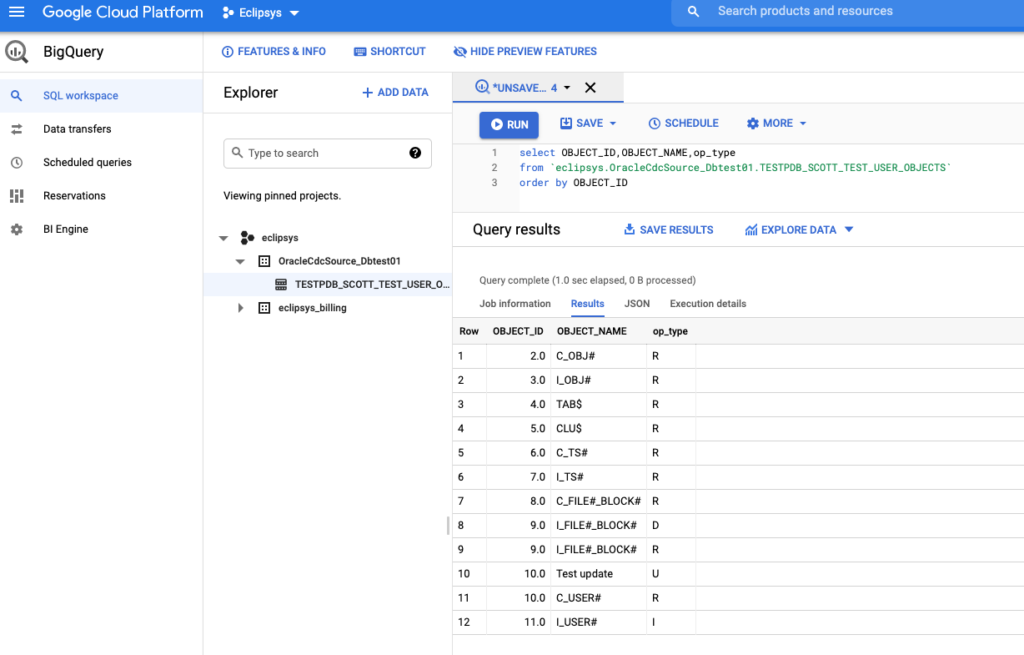
It was working fine and replicating all the new operations with the corresponding flags for delete, insert and updates. As you can see by default the replication is rather a journal of changes when you can get the state of the table for any given time using op_type, op_ts and current_ts columns. But if we want we can use upserts and deletes for the replication and it will merge those in a regular fashion to keep a state for the table.
That was the first and very basic test of functionality. I have been working on other tests and probably will post some results in future blogs. For example, I found the connector can get stuck and you need to restart the task to get it back to normal and continue to replicate the data. Stay tuned and happy testing.
Terraform is probably already the de-facto standard for cloud deployment. I use it on a daily basis deploying and destroying my tests and demo setups ... Read More
If you’ve been following the recent changes in the Linux world you probably remember how Red Hat and Centos announced in December 2020 that the ... Read More



